Overview
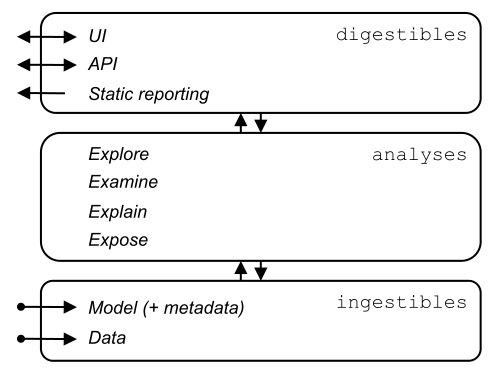
The Explabox aims to provide insights into your data and model behavior, by transforming ingestibles into digestibles through four types of analyses. The Explabox is split into three layers:
A full explanation of the functionalities is included in the Journal of Open-Source Software (JOSS) paper:

Ingestibles
Ingestibles encompass your model and data. The Ingestible class provides a unified interface for accessing your model (e.g. its meta-information and prediction function) and your data (e.g. the instances, the various splits, and corresponding ground-truth labels). Ingestibles contain meta-information of the data and model (to determine relevant functions for analyses and for auditability) and allow for optimized inferencing through batching and lazy loading.
Importing ingestibles
The model can be imported via the import_model() function, while the data is imported via the import_data() function.
Supported models are:
Scikit-learn
ONNX (supports TensorFlow, PyTorch, HuggingFace, Scikit-Learn, …)
Python callables
Supported data are:
NumPy arrays
Pandas DataFrames
HuggingFace datasets
Files (online or offline):
Tabular dataset files (
.csv,.tsv,.json,.txt,.xls,.xlsx, …)Folders or archived files (
.zip,.rar,.gzip, …) containing multiple dataset filesPickled Python objects (
.pkl)HDF5 files
Analyses: turning ingestibles into digestibles
Once imported, these ingestibles can be made more informative by turning them into digestibles. Each analysis provides functions to enhance the transparency of the model and/or data:
Analysis |
Class |
Description |
Requires |
|---|---|---|---|
|
|
The Explorer explores your data by providing descriptive statistics. |
data |
|
|
The Examiner calculates quantitative metrics on how the model performs. |
data, model |
|
|
The Explainer creates explanations corresponding to a model and dataset (with ground-truth labels). |
data, model |
|
|
The Exposer exposes your model and/or data, by performing sensitivity tests. |
data, model |
The Explabox class is a unified interface for all of these classes, where an instance of each of these classes is
constructed. These can be accessed via .explore, .examine, .explain and .expose, respectively.
For example, using the Examiner one can obtain (for a classification task) all instances wrongly classified by the model, which returns the WronglyClassified digestible:
>>> from explabox.examine import Examiner
>>> Examiner(ingestibles=ingestible).wrongly_classified()
Digestibles
Digestibles are the return type after performing an analysis. The information contained in them can be accessed in various ways (i.e. interactively or statically), depending on stakeholders needs. Example methods of access include:
Python object (i.e. the raw property values)
Object descriptions:
JSONYAMLPython dictionary
User interfaces (using plots rendered with
plotly):HTML
Jupyter Notebook
When using an interactive Python shell, the Explabox will default to the Jupyter Notebook interface. In a non-interactive Python shell the Python object is the basis for the digestible. For online applications (e.g. streamlit) the HTML interface can be used.